30 Jun How to Speed Up Data Delivery in Modern DevOps Pipelines
Kirby Wadsworth
Kirby has more than two decades of marketing leadership in both publicly traded large enterprises and emerging startups. As a founder and early venture executive with several successful exits, Kirby helped pioneer the cloud storage, continuous data protection, and file virtualization industries.
DevOps pipelines are the backbone of innovation. Ensuring a fast, effective, and secure pipeline is critical for the overall success of an organization. In order to stay relevant in rapidly changing markets and keep up with dynamic customer demands, modern DevOps pipelines need to focus on speeding up data delivery.
Let’s face it. There is a direct correlation between application release speed and revenue. This is one of the main reasons why enterprises spanning all industries have championed DevOps as the ultimate guiding force for bringing solutions to market quickly and efficiently. The key to fulfilling the true promise of DevOps is to automate data delivery to speed up the entire deployment pipeline. Faster data delivery can be achieved with innovative automation solutions such as Kubernetes Native Storage (K8sNS). In this article, we’re going to show you how to use K8sNS to accelerate your DevOps pipeline by boosting the speed of data delivery.
Data as Code Speeds Up Data Delivery
DevOps engineers want the data they need, when they need it. The main problem encountered here is the large gap of time between stages in a CI/CD pipeline where data is reassembled, copied, replicated, moved, and migrated. Depending on the circumstances, this time can range from a few hours to over a week leading to major deployment delays.
With instant copy of applications across clouds and instant clones at one-second granularity, deployments are empowered with rapid data delivery for development acceleration and testing. Basically, DevOps teams can customize how a data environment will be deployed at a certain stage in the CI/CD pipeline. With the right framework, DevOps teams can decide if new builds should rewind to previous data from yesterday or earlier to execute a system testing environment or if a full refresh from production is necessary for user acceptance testing environments. Because of this, development environments like Jenkins and Bamboo can better scale, accelerate app delivery, and instantly move data from development to production.
Copying Data From Place to Place
Data mobility enhances data delivery by enabling full volumes of data to be copied and moved to a new location anywhere in the world in just a few seconds. Commonly, developers have to wait until the end of the pipeline to test their data. If the data fails, it’s likely the DevOps team would need to start the majority of the pipeline over.
With Kubernetes Native Storage, developers are equipped with the flexibility to perform tests against full, accurate, copies of data throughout the development process. By giving developers the freedom to test, refresh, branch, or share their data copies enables the necessary collaboration between the DevOps and Security teams to develop secure and adequate deployments in a timely manner.
Let’s take a look at how Kubernetes Native Storage enables the migration of data from one place to another in seconds. Below is a graphic representation of data moving from Washington, D.C. to Dublin, Ireland in less than 40 seconds.
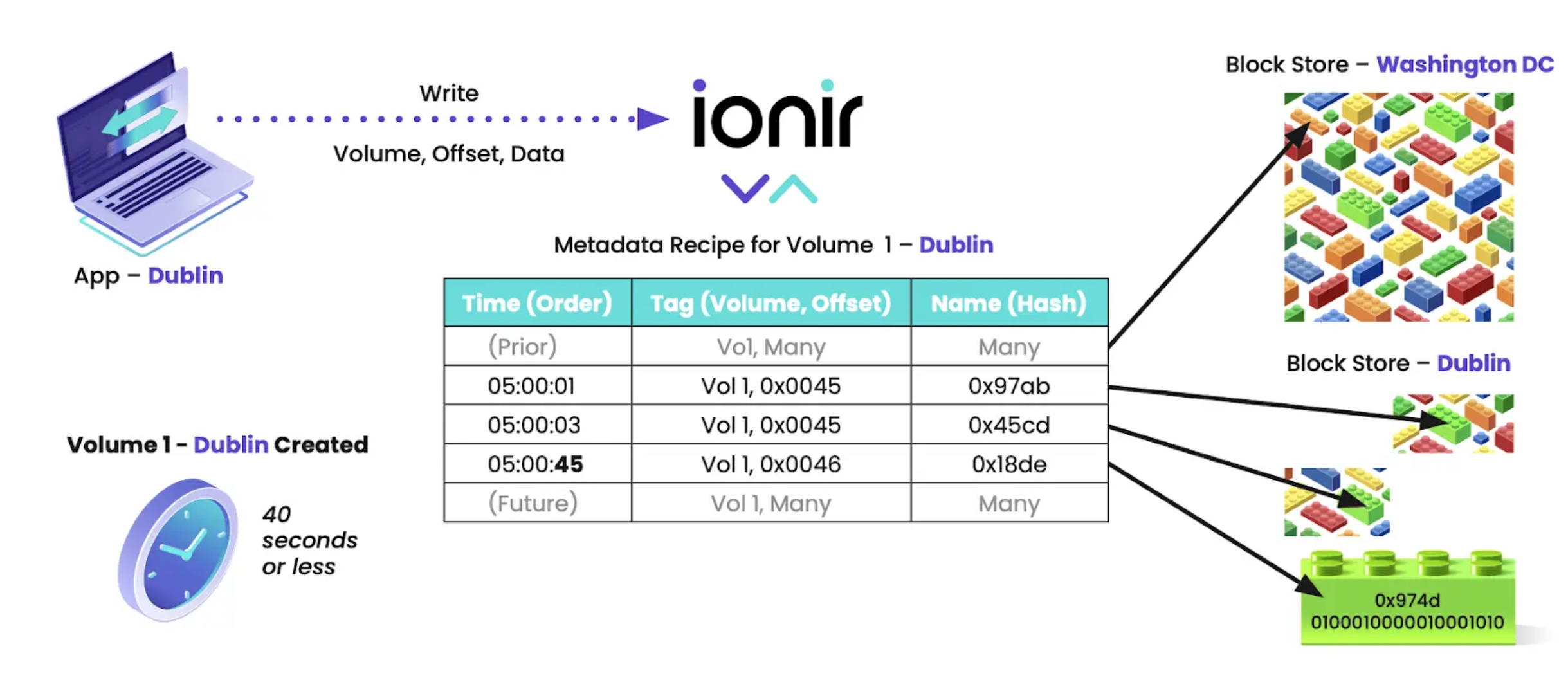
Here’s how it goes down with just one click:
First, another metadata set for Volume 1-Dublin is created. Next, “hot blocks” are copied to Dublin to seed Volume 1. “Hot blocks” prioritize which pieces of data will need to be used first based on a “heat map” of the most used data blocks. This ensures the data will be instantly available at the new location.
Moving on, the new writes are stored immediately in Dublin as Volume 1 rehydrates in the background. Finally, with the additional help of global deduplication to minimize egress, a full Volume 1 is ready and available for the DevOps team to access in Dublin. This timely data delivery ensures the automatic provisioning and refreshing of data environments to avoid release bottlenecks or a delay in the CI/CD pipeline.
Provisioning Data at Any Point in Time
The DevOps team also benefits from Kubernetes Native Storage’s ability to provision data at any point in time. Not only does this help speed up data delivery, it also aids in troubleshooting, recovery, and testing environments. By keeping a granular history of data changes, K8sNS is able to go back in time to access a copy of the data at a previous point in time.
For example, let’s say some form of malware or bug got into your latest data volume or block and your team needs to recover the volume before the malware can infect any further data. With the ability to access data at any point in time, K8sNS can actually return to a copy of a previous data volume that reflects the block’s last known “good state” — basically, a former state where the data was performing optimally. This capability eradicates any issues and restores lost or corrupted data back to production. Ultimately, accessing data at any point in time enables developers to test patches and recover from corruption for a faster and more cost-effective mean time to recovery.
So how is this accomplished? Let’s take a look!

With no need to snapshot, backup, or restore, developers are able to request a copy of data at a particular time. The example above depicts how data can be accessed just seconds before the corruption occurred. Let’s say one of your employees clicked on a ransomware email and your data started being encrypted. Once a request is made to access data at a time before the malware infiltrated, a new metadata recipe is created, i.e. Washington, D.C. Volume 1 (5:00:01). From here, the clock is basically reset and the malware is — poof! — gone as if the corruption never even happened.
Final Thoughts
Modern DevOps pipelines require a mature system of tools and automated processes. Kubernetes Native Storage is the key to enabling collaboration between DevOps and Security teams, accelerating the speed of data delivery, and rapidly delivering innovations to market. Ultimately, ionir K8sNS cuts data delivery time from hours or days to just seconds and improves data agility enabling quick data delivery to accelerate CI/CD pipelines.
Accelerate your CI/CD pipeline with Kubernetes Native Storage and experience accurate and secure deployments faster than ever before. Contact us to get started with your free ionir download to make your data move as fast as you need it to.