15 Feb Bursting MongoDB to a Remote Kubernetes Cluster in Minutes: Part 2 — Teleport and Scale
Barak Nissim
With over 15 years of IT experience from core datacenter infrastructure to advanced cloud technologies, Barak leads ionir’s product and solutions portfolio, engaging with customers, partners, and acts as cloud-native storage advocate.
In part one of this series, we left off the environment with one cluster with a StatefulSet of MongoDB deployed on ionir data volumes and no workloads on the second Kubernetes cluster.
In part two of this series, we will scale MongoDB to the second Kubernetes cluster in another data center, as recommended by MongoDB. In addition, we will add an Arbiter service.
To protect your data in case of a data center failure, keep at least one member in an alternate data center.
Primary-Secondary-Arbiter
In a demo, we designed a PSA (Primary-Secondary-Arbiter), as a minimum config to show failover, you can read about it here. To deploy an Arbitrator, we need to deploy this example YAML file:
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: mongo-arbitrator
labels:
appdb: mongo-arbitrator
spec:
replicas: 1
selector:
matchLabels:
app: mongo-arbitrator
serviceName: mongo-arbitrator
template:
metadata:
labels:
app: mongo-arbitrator
spec:
terminationGracePeriodSeconds: 10
containers:
- name: mongo-arbitrator
image: mongo
command:
- mongod
- "--storageEngine"
- wiredTiger
- "--bind_ip_all"
- "--replSet"
- "rs0"
ports:
- containerPort: 27017
volumeMounts:
- name: mongo-data
mountPath: /data/db
volumeClaimTemplates:
- metadata:
name: mongo-data
spec:
storageClassName: ionir-default
accessModes: [ "ReadWriteOnce" ]
volumeMode: Filesystem
resources:
requests:
storage: 40Gi
---
apiVersion: v1
kind: Service
metadata:
name: mongo-arbitrator
labels:
app: mongo-arbitrator
spec:
type: LoadBalancer
loadBalancerSourceRanges:
- 0.0.0.0/0
ports:
- name: mongo-arbitrator
port: 27017
targetPort: 27017
selector:
app: mongo-arbitrator
sessionAffinity: None
On your master MongoDB node, you will see another member is populated on the result of rs.status().members command with “arbiterOnly” : true.
On our second cluster, in the remote data center or cloud region, let’s apply just a MongoDB service to make sure we receive a DNS/IP for the planned Secondary of the ReplicaSet (we do not deploy the StatefulSet yet):
apiVersion: v1
kind: Service
metadata:
name: mongodb
labels:
app: mongodb
spec:
type: LoadBalancer
loadBalancerSourceRanges:
— 0.0.0.0/0
ports:
— name: mongodb
port: 27017
targetPort: 27017
selector:
app: mongodb
sessionAffinity: None
Now, to configure the new ReplicaSet to work in PSA, we will run the following reconfiguration on the Primary:
cfg = rs.conf();
cfg["members"] = [{
"_id" : 0,
"host" : "Primary-service-externalIP:27017″,
"priority" : 100,
"votes" : 1 },
>{
"_id" : 1,
"host" : "arbiter-service-externalIP:27017″,
"arbiterOnly" : true,
"priority" : 0,
"votes" : 1
},
{
"_id" : 2,
"host" : "Secondary-service-externalIP:27017″,
"priority" : 10,
"votes" : 1 }]
rs.reconfigForPSASet(2, cfg);
Notice we have configured the third member with ”priority” : 10, ”votes” : 1 this will make sure it will remain Secondary.
Make sure you edit the right hosts’ names under each member.
Turning on the Secondary Node
At this moment, we have all configurations in place, and it’s time to introduce our “Bursted-node” to the setup. But before we do so, we have configured a simple DNS failover using Route53 to enable an easy and seamless transition between replicas in the replicaSet. The failover is based on a health check for the Primary node ExternalIP LB service.
To add a host to the replicaSet, the only thing we need to do is to deploy the MongoDB YAML as it appears in part one, now on our remote cluster. The service is already in place, and the engine will add the new host and start replicating data to it.
Moving the data between clusters can take hours, depending on size and distance, of course. The common alternative is to bring the new node using backups. But that involves running the backup jobs, waiting for them to finish and sync, or depending on old data, which sometimes is almost not relevant at all to the current state of the data.
ionir Teleport and Data Mobility
This is where the ionir magic comes into play. Using ionir Teleport the remote MongoDB host will get an up-to-date clone of the data in under 40 seconds, no matter the size or distance.
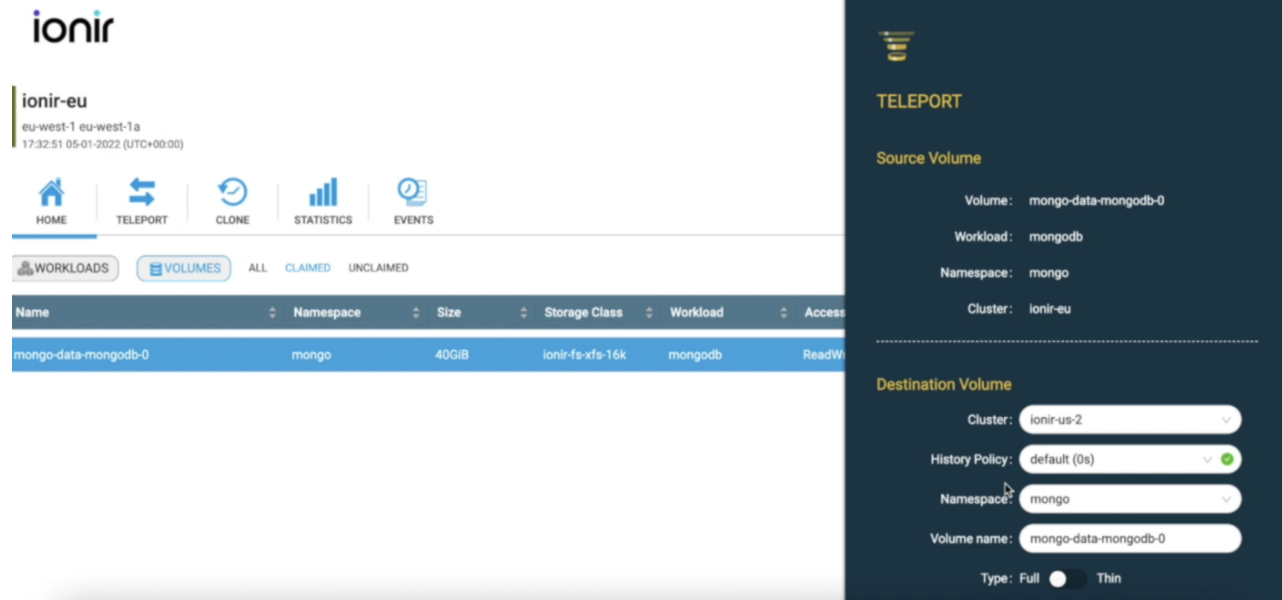
The only additional step needed to be performed is teleporting the volumes using ionir UI (or a single REST API call) from Cluster A (ionir-eu) cluster to Cluster B (ionir-us-2) Kubernetes cluster. That’s it — and 40 seconds later we can start our MongoDB StatefulSet on Cluster B with a full representation of the data. In the background, the ionir engine will take care of the heavy lifting of actually moving the data between clusters.
The entire process takes a couple of minutes, and we can see using rs.status().members on the master that the new node is reaching Secondary state and starts serving queries. This bursting exercise can be performed, automatically or manually, to multiple target sites, clusters or cloud providers on-demand — this is the power of Kubernetes Native Data Services.
Final Thoughts
In the next and final part of this series, we will demonstrate a failover scenario using our newly configured ReplicaSet and DNS failover to seamlessly migrate end-users from one cluster to another.