25 Oct Data Services: Making Data More Mobile, Accessible, and Resilient (Part Two)
Kirby Wadsworth
Kirby has more than two decades of marketing leadership in both publicly traded large enterprises and emerging startups. As a founder and early venture executive with several successful exits, Kirby helped pioneer the cloud storage, continuous data protection, and file virtualization industries.
In part one of this series on data services, we introduced the idea of data characteristics and the importance of the Location characteristic. With a better conceptual understanding of data location — and the ability to replace physical location with virtual — we opened up the possibility of moving the access point to a set of data in advance of moving the actual bulk of ones and zeros at the core of the dataset. The implications here are enormous. Datasets can now move freely and at will. We can achieve location independence for data that approximates the location freedom that applications enjoy in today’s cloud metaverse.
Rearranging Data Sets According to Time
Now, let’s turn our sights on another, perhaps more powerful characteristic of data, its TIME. What if we could instantly rearrange the individual datum in a set according to time? What if we could include or exclude groups of data from a set in such a way that the full contents of the new data set represented the original contents of that set as it existed at a previous moment in time?
We would have an immutable and yet fluid dataset — impenetrable by attackers, resilient in the face of accidents, errors, deletion, and overwrite.
At ionir, we have built such a machine, capable of high-performance real-time data operations, yet able to instantly produce cloned datasets matching previous states of the original. All this is accomplished by adding the powerful new data characteristic of Time to every write.
The graphic below demonstrates data gravity and how ionir frees data to instantly move anywhere in time and place.
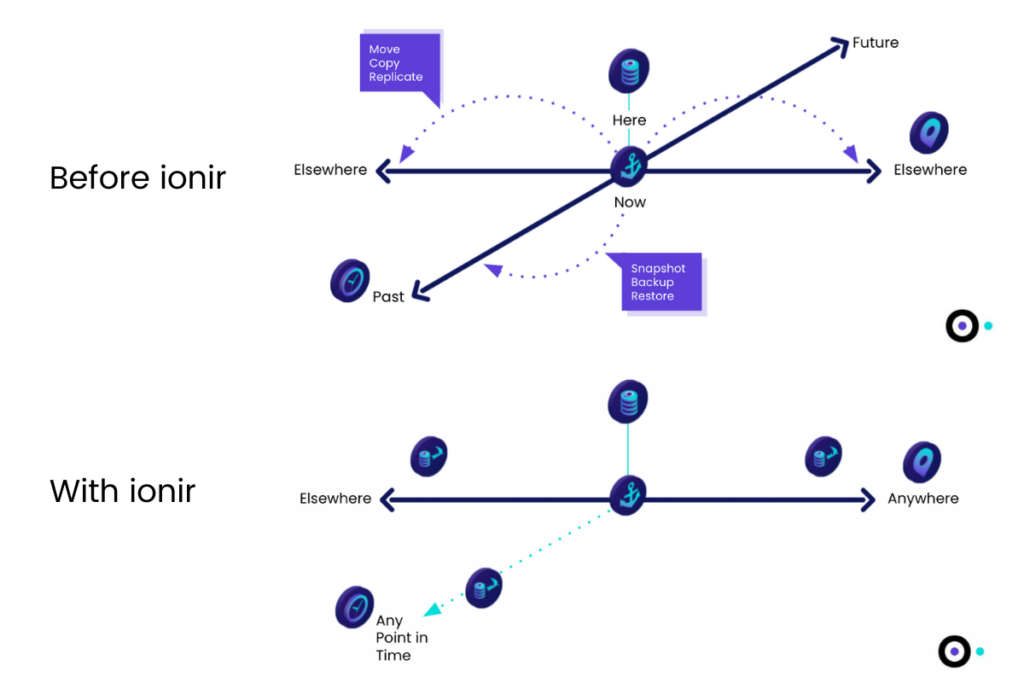
To gain a full understanding of how your data can be accessed — no matter where it’s located — in 40 seconds or less, download our resource, The Before vs. After When Implementing ionir’s Kubernetes Data Services Platform.
Data Services Work with Kubernetes to Increase Agility
Software-defined data services platforms such as ionir enable developers to access data without concern for its physical location and to reset data instantly to earlier states.
Furthermore, Kubernetes-native data services platforms offer services that are required to effectively scale enterprise apps in Kubernetes such as:
- Persistence
- Protection
- Replication
- Global deduplication
- Compression
The ionir platform offers these services at enterprise scale. Let’s take a look at how ionir makes data more agile and accessible for developers.
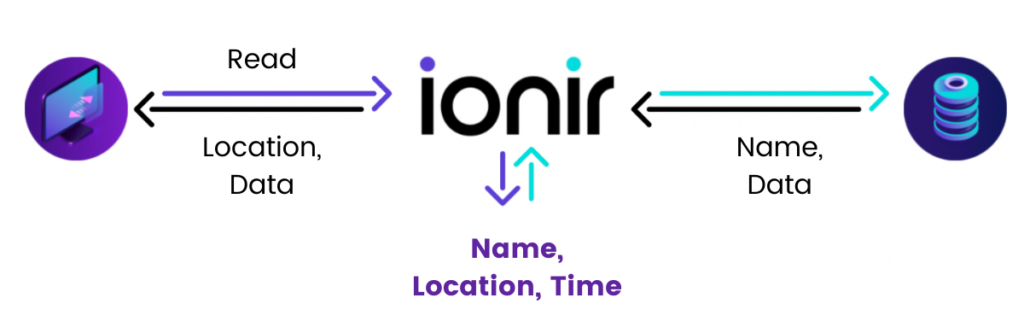
First, the Kubernetes CSI (container storage interface) requests a volume from a specific time or location. Within seconds (40 or less), a fully read/write-capable volume of data as it existed at that exact requested moment in time is made available to Kubernetes applications.
Check out our blog, Kubernetes Native Storage: What It Is, How It Works, and Why It Drives Digital Transformation, to see the in-depth details on how ionir works.
How Do Data Services Benefit DevOps Initiatives?
Data services are especially useful when it comes to recovering data that has been affected by ransomware, corruption or other data loss. For example, if a block of data is corrupted at the timestamp 5:00:01, the best data services platforms enable volumes to be accessed at their most ideal state. Therefore, the volume of data can be accessed and regressed to the timestamp 5:00:00.
Additionally, data services streamline the development pipeline and enable a quicker time to deployment. These services ensure consistent test data across all stages of the CI/CD pipeline. Ultimately, this results in:
- Simplified workflows
- Increased productivity
- Reduced time to market
Final Thoughts
Now more than ever, data services are proving to be beneficial to DevOps organizations spanning all industries. With the ability to access data at any point in time or space, protect data from corruption, and retrieve data in 40 seconds or less, ionir is spearheading the movement with extensible and scalable data services.
Want to see the efficiencies ionir can bring to your pipeline? Start your free trial of ionir today.